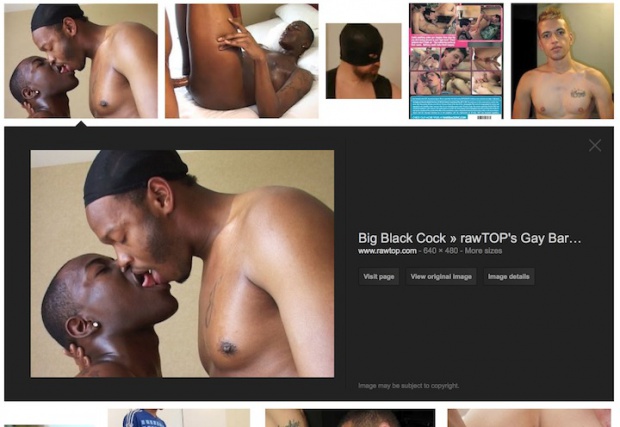
In case you didn’t notice, Google Images changed in the past month. Now, when you click on an image in the SERPs it expands and shows a larger version of the image and gives you the option of what you want to do. It now looks something like this…
That big image is hotlinked off your server. On top of that if you click “View Original Image” the user goes directly to the image and skips the page that the image was on.
Complicating all of this is that it’s more difficult to identify which traffic is coming from Google Images. The referral URLs are almost identical take a look at a regular search URL and an image search URL and tell me what the difference is - I can’t figure it out.
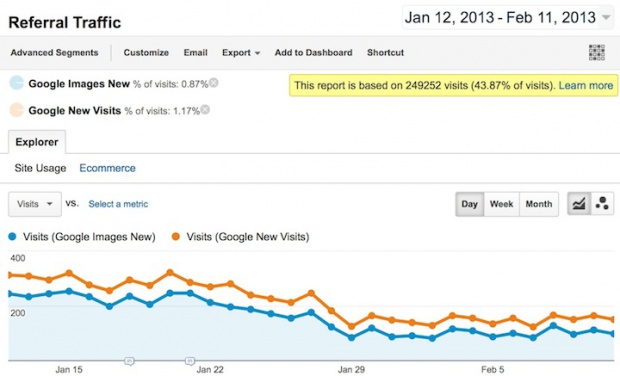
But either way you look at it, real traffic (the person actually comes to your page) is down substantially…
That’s total Google referral traffic (not including organic search, etc.) and traffic that I know for sure is Google Images traffic. My Google Images traffic is down 58% and my overall Google referral traffic is down 50%.
So the question is 1) does it make sense to participate in Google Images anymore? and 2) what’s the proper response?
They’re stealing bandwidth (since they’re serving my full-size images on their website) and sending less traffic. I’ve got hotlink protection in place. I think I’ll remove Google from the list of approved hotlink hosts. That will result in the user seeing an image that says “stolen image” rather than the real image when an image is displayed in a page served by Google. The problem is that when they come to my site that image will still say stolen unless they refresh the page.
I think at the end of the day I’ll do a 302 to a graphic that says “Click Here to see the full size image”. The user doesn’t need to be lectured that Google is stealing the image, and I want to try to avoid being deindexed since there is some real traffic coming from Google Images.
Actually, thinking about it, my solution of serving a “Click here to view image” graphic won’t work because the hotlinked image looks the same to my server as when the user clicks “View Original Image”. Problem is, when they click clicking again won’t do anything since they’re not on an HTML page.
I’ve seen others commenting about the same problem, with Google effectively stealing content to present as their own, while offering nothing back.
It would be great if you could post up the process you decide on. I will be looking into doing this on my own sites from now on too, having seen the decline from Google over the last couple of weeks.
I know how to manage the hotlinking thing, but I’m not sure how you change the image to show something custom.
[QUOTE=conran;128940]It would be great if you could post up the process you decide on. I will be looking into doing this on my own sites from now on too, having seen the decline from Google over the last couple of weeks.
I know how to manage the hotlinking thing, but I’m not sure how you change the image to show something custom.[/QUOTE]
I want a solution like fanshare.com has… Just have to figure how how they managed to do it. It’s quite elegant…
Supposedly someone asked fanshare tand they responded ".htaccess and PHP+GD Library is applied to achieve the function, + functions as imagecopymerge() was a big one in recreating the opacity overlay! "
There is some good info there that may help in dissecting this.
A bit more info… Bing’s image search is even worse than Google’s. They just show a thumbnail of the page it came from down in the corner. If you click on the image you get taken to the original image, not the page with the image. Yahoo’s is even worse than Bing - there’s just a tiny little link down in the corner with a link to the page - nothing else leads to the page. and, of course, they’re hotlinking original images…
There’s another problem though…
[SIZE=2]The thing is that google started to use https even for logged-off users. And the problem with https is that it sends no referral data :-/ So the images are being stolen and the server thinks they are just direct requests.
[/SIZE]
[SIZE=2]For everybody out there trying to block Google’s hotlinks through htaccess - I just did some experiments and according to my Apache logs, when Google Images loads an image, the referrer is left blank. I don’t mean blank as in: “http://www.google.com/blank.html” - I mean blank as in “-”.
This sorta says to me that unless you block all blank referrers, which could have some unintended consequences, there isn’t any way to intercept those requests.
So there are two [SIZE=2]Wordpress plugin[SIZE=2]s that try to deal with this - “Google Break Dance” and “[/SIZE][/SIZE][/SIZE][SIZE=2]Imaguard” - can’t vouch for either one an[SIZE=2]d [SIZE=2]since I don’t use Wor[SIZE=2]d[SIZE=2]press to upload images [SIZE=2]to my blo[SIZE=2]gs, they won’t work for me, so I won’t be testing them, but they may be the easiest way to deal with the problem on your blogs.
I’m still thinking[SIZE=2] about th[SIZE=2]e problem[SIZE=2]… Hav[SIZE=2]en’t come up with a solution I feel comfortable with yet[SIZE=2]…[/SIZE][/SIZE][/SIZE][/SIZE][/SIZE]
[/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][SIZE=2]
[/SIZE]
Given that there’s no referrer when some is viewing in Google Images, I’m not quite sure how reliably it will work.
Another solution that seemed elegant was to check for a some type of session cookie. If it’s not there, then serve a watermarked image. But that doesn’t fix the problem of them clicking directly to the image.
You could add a type-in watermark to the corner of the image to try and recoup some of the traffic stoppage. That might be against the producers’ affiliate program’s terms though.
Sooooo… it’s looking like what shows up in the Apache logs is dependent on which browser you’re using.
For those of you who [SIZE=2]thin[SIZE=2]k that looks like [SIZE=2]Greek[SIZE=2]… Those are [SIZE=2]server log[SIZE=2] request[SIZE=2]s from Google [SIZE=2]Images. [SIZE=2]Notice that only IE is giving referrer data. Both Chrome and Firefox give [SIZE=2]"[SIZE=2]-" as the referrer. [SIZE=2]That really complicates [SIZE=2]implementing a solu[SIZE=2]tion[SIZE=2] since you can’t say conclusiv[SIZE=2]ely [SIZE=2]when something is hotlinked off Google Images.[/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE][/SIZE]
[/SIZE]
This works via <img src> tag or if you visit the URL’s directly.
If FanShare can differentiate between a hit coming from an <img src> tag or for example a Google Search (source=images) they can go even further and redirect you from the watermarked image to the actual page they want you on.
On a side note I noticed that FanShare also provides Google Bot with different HTML than users. When I visited the site and set my browser to send Google Bot Headers the image URL’s are different.
By providing Google with URL’s to the image located on FanShare’s server FanShare can now adjust what happens at a server level when someone tries to visit the locale copy of an image rather than the CDN version.
Hope that helps…
PS When I visited FanShare as Google bot all their images had the watermark. So Fan Share is pretty much saying if your asking for images off from our server your getting a watermarked copy. (ie Search Engines). If your an actual visitor you get the non watermarked CDN version.
Kevin… Yes, I saw on WW that Fanshare is basically cloaking…
Regular users get HTML with CDN-based image URLs to unwatermarked images.
Googlebot gets unwatermarked images with non-CDN URLs.
Regular users requesting non-CDN URLs (they got from Google Images) get watermarked images.
So basically the CDN URLs are only given out to legit users who come to the site. The CDN images are always unwatermarked. But they give different URLs to googlebot and anyone who uses those URLs gets a watermarked image (except googlebot which gets an unwatermarked version).
I’m just thinking - UGH - you mean I seriously have to come up with two versions of every image on my site? Seriously? And even if I did that, how do I rewrite the URLs in something like Wordpress?
But that doesn’t answer another question I have about the Fanshare solution - when you click on “view original image” you get taken to the page, not the image. Without referrer data - how do they do that?
You guys are WAY over-complicating this. If you want to replicate what FanShare has done, I’ll code it for you in exchange for you signing up as an affiliate and promoting my new site on IndieBucks: CrushHim :whistle:
[QUOTE=rawTOP;128970]Kevin… Yes, I saw on WW that Fanshare is basically cloaking…
Regular users get HTML with CDN-based image URLs to unwatermarked images.
Googlebot gets unwatermarked images with non-CDN URLs.
Regular users requesting non-CDN URLs (they got from Google Images) get watermarked images.
So basically the CDN URLs are only given out to legit users who come to the site. The CDN images are always unwatermarked. But they give different URLs to googlebot and anyone who uses those URLs gets a watermarked image (except googlebot which gets an unwatermarked version).
I’m just thinking - UGH - you mean I seriously have to come up with two versions of every image on my site? Seriously? And even if I did that, how do I rewrite the URLs in something like Wordpress?
But that doesn’t answer another question I have about the Fanshare solution - when you click on “view original image” you get taken to the page, not the image. Without referrer data - how do they do that?[/QUOTE]
If you don’t want two versions of every image there are scripts that will watermark on the fly. Of course this method could add some pretty significant overheard to your server load if you have any decent amount of images being viewed externally that would hit this script. Much easier for server to serve static images.
[QUOTE=britton;128973]mod_rewrite via .htaccess replacing the image with a script generated image.
You can also make visiting an image directly go to a page with your ads (or if wordpress, the page featuring that image)[/QUOTE]
How do you differentiate between 1) a direct link to an image, and 2) a hotlink that doesn’t pass referrer info, and 3) a regular surfer who’s browser doesn’t send referrer data? A cookie can be used to figure out whether they’re #3 (if they send cookies - if they’re so paranoid they turn off referrer data, they may not pass cookies). But with #1 you want to send an alternate image, with #2 you want to redirect to a page. I can’t figure out how to differentiate between #1 & #2…
[QUOTE=mountequinox;128974]Easy
They have the URL to the page they are looking for pretty much within the URL to the image.[/QUOTE]
So in other words, if you don’t know a URL associated with the image you’re shit-out-of-luck…

{kind=link}